Thomson Reuters US Legal Bookstore
Top selling Publishers
Explore what's new & noteworthy
Presidents Day sale
Save 30% on your order.* Enter code PRES30 at checkout to apply your discount. Offer expires at 11:59 pm CT on February 17, 2026. Savings apply to a wide variety of legal print and ProView titles. Product exclusions apply, which can be found on the cart page during checkout.
Westlaw Today SCOTUS Spotlight
Access timely, in-depth reporting on important Supreme Court cases from the 2024 term—eliminating the need to review lengthy opinions or consult multiple sources.
Bundle and Save with ProView and Print
Save 35% or more by bundling ProView and physical books. Unlock the maximum flexibility to research wherever work takes you. Bundle and save with ProView e-books and physical books. Find the answers you trust in the format that best suits your research needs.
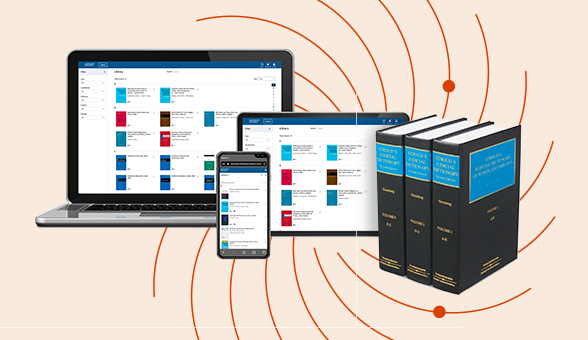
Check out our latest legal essentials on our ProView eBook reader.
Enjoy a consistent, book-like reading experience with ProView on any device: laptop, smartphone, tablet, or desktop. Perfect for legal professionals who need reliable access to trusted content anytime, anywhere.
Shop All O'Connor's Titles
O’Connor’s books offer concise editorial insights and practical commentary on the most essential Texas legal topics to help simplify your legal research.
Black's Law Dictionary
The world's leading legal reference book, redefined.




Presidents Day sale
Save 30% on your order.* Enter code PRES30 at checkout to apply your discount. Offer expires at 11:59 pm CT on February 17, 2026. Savings apply to a wide variety of legal print and ProView titles. Product exclusions apply, which can be found on the cart page during checkout.
Westlaw Today SCOTUS Spotlight
Access timely, in-depth reporting on important Supreme Court cases from the 2024 term—eliminating the need to review lengthy opinions or consult multiple sources.
Bundle and Save with ProView and Print
Save 35% or more by bundling ProView and physical books. Unlock the maximum flexibility to research wherever work takes you. Bundle and save with ProView e-books and physical books. Find the answers you trust in the format that best suits your research needs.
Check out our latest legal essentials on our ProView eBook reader.
Enjoy a consistent, book-like reading experience with ProView on any device: laptop, smartphone, tablet, or desktop. Perfect for legal professionals who need reliable access to trusted content anytime, anywhere.
Shop All O'Connor's Titles
O’Connor’s books offer concise editorial insights and practical commentary on the most essential Texas legal topics to help simplify your legal research.
Black's Law Dictionary
The world's leading legal reference book, redefined.
Shop by jurisdiction
Pinpoint the resources legal professionals need in your jurisdiction
National
Federal
California
New York
Texas
Florida
Shop by categories
Find specialized titles designed for multitude of practice areas
Bankruptcy law
Criminal law and procedure
Labor and employment law
Estate planning
Family law
Real estate law
Key resources

Customer support
Got questions or need help? Our customer service team is here to help. 1-888-728-7677
Contact support

Contact Sales
We can help you with your questions about Thomson Reuters Print titles.
Contact sales

Log in to Proview
Not your first e-book purchase? Log in to Proview and access your library.N
ProView resources